
How to Display Beautiful Table Data with Python and Pandas
You can make Pandas DataFrames look publication-worthy - Here's how!

I don’t like many things about R, but it’s just plain better than Python for visualizing table data.
With some digging and manual labor, you can transform boring Pandas DataFrames into publication-worthy tables. The way to do so isn’t intuitive and isn’t discussed in many places. It’s a shame, as most of us don’t want to export data to Excel to make them look decent.
That’s where this article comes in.
After reading, you’ll know exactly what goes into styling Pandas DataFrames and you’ll have code snippets for style tweaking ready to plug into any DataFrame.
If you’re a paid subscriber, you can skip the reading and download the notebook instead.
The Dataset
Before diving into the good stuff, we have to take care of the dataset. The code snippet you’ll see below creates one for you. It has four columns, each having 5 arbitrary values. Some values are missing as well, for the reasons you’ll see shortly:
import numpy as np
import pandas as pd
df = pd.DataFrame({
"A": [0, -5, 12, -4, 3],
"B": [12.24, 3.14, 2.71, -3.14, np.nan],
"C": [0.5, 1.2, 0.3, 1.9, 2.2],
"D": [2000, np.nan, 1000, 7000, 5000]
})
dfHere’s what the dataset looks like:
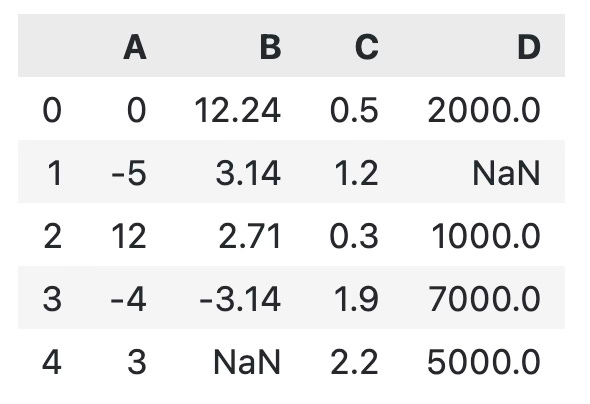
It’s a pretty standard Pandas output, one which looks familiar and, let’s face it, boring. Up next, you’ll learn how to spice it up.
Basic Formatting with Pandas Styles
Pandas packs a Styles API that allows you to change how the DataFrame is displayed. There are many built-in styling functions, but there’s also the option to write your own.
One thing I find annoying most of the time is the index column. It’s just a sequence, and provides no real-world value for table visualization. Use the hide() method to get rid of it:
df.style.hide(axis="index")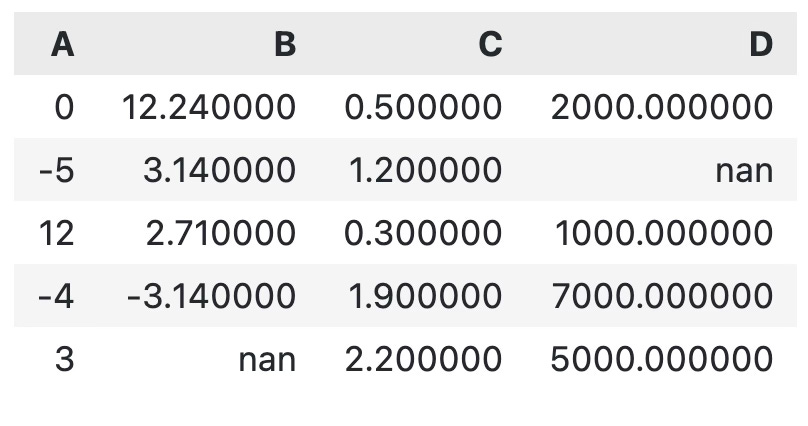
Much better!
There are other things that make our DataFrame painful to look at. For example, the precision of these decimal numbers is unnecessary. For visualization purposes, two decimal places are enough most of the time:
df.style.format(precision=2)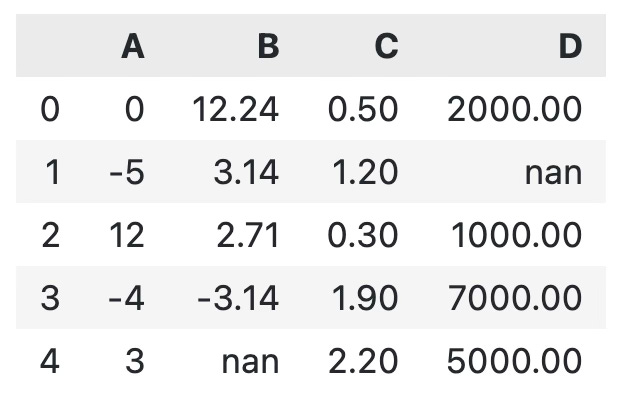
You can take the whole story a step further and specify a custom formatting string. The one below will add a minus sign before and after each value, and also format each number to three decimal places:
df.style.format("- {:.3f} -")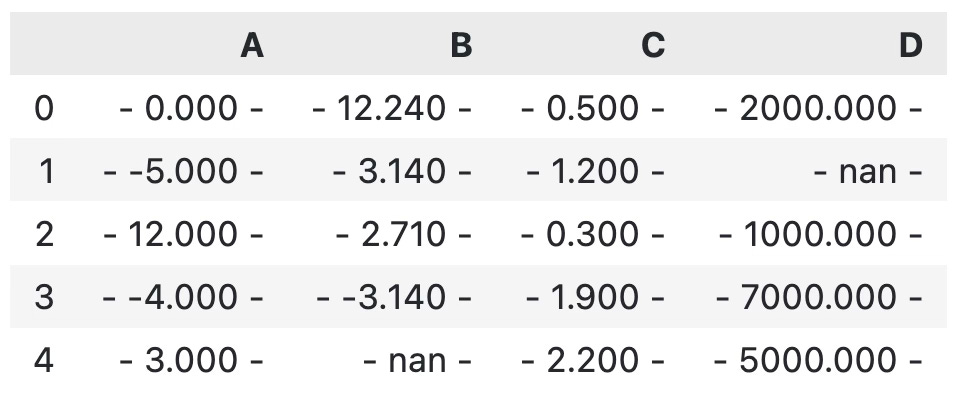
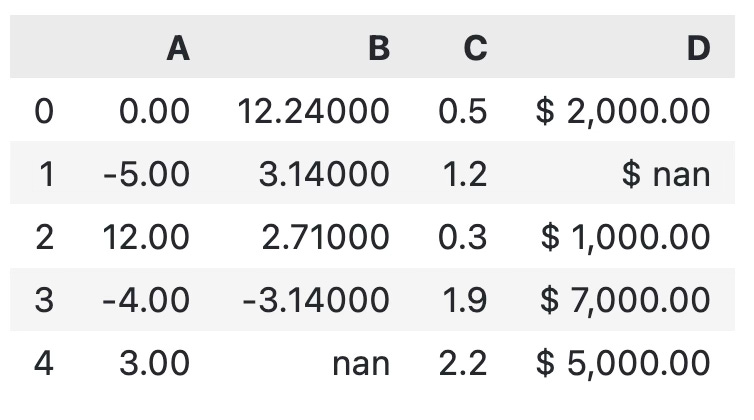
Things don’t end here. Sometimes, you want different formatting for each column. Specify the formatting string as key-value pairs and you’ll be good to go:
df.style.format({
"A": "{:.2f}",
"B": "{:,.5f}",
"C": "{:.1f}",
"D": "$ {:,.2f}"
})
That does it for the basics of formatting. Next, we’ll go over numerous ways to change the text and background color — and much more.
Use Pandas Styler to Change Text and Background Color
Usually, it’s a good idea to highlight data points you want to draw attention to. The convenient highlight_max() function assigns a yellow color to the largest value of every cell in a DataFrame:
df.style.highlight_max()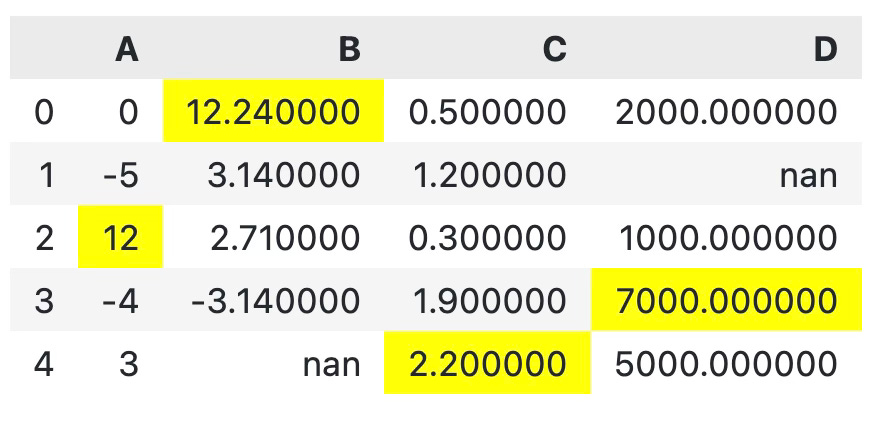
The highlight_min() function does just the opposite:
df.style.highlight_min()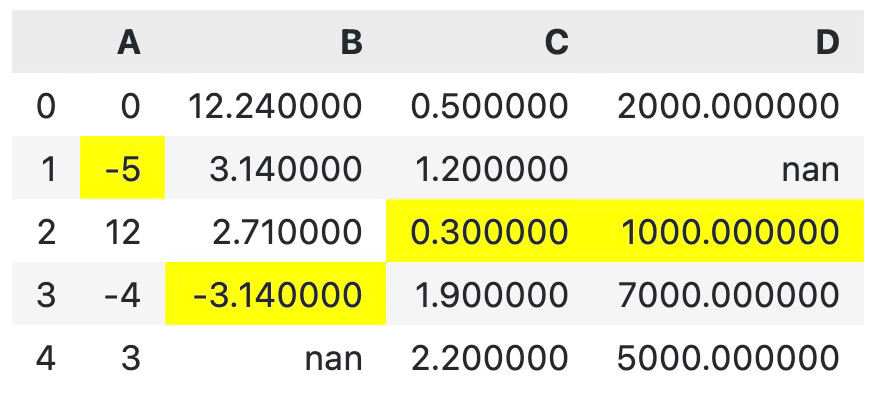
In addition to min and max data points, you can also highlight the missing values. The example below shows you how to color cells without a value in red:
df.style.highlight_null()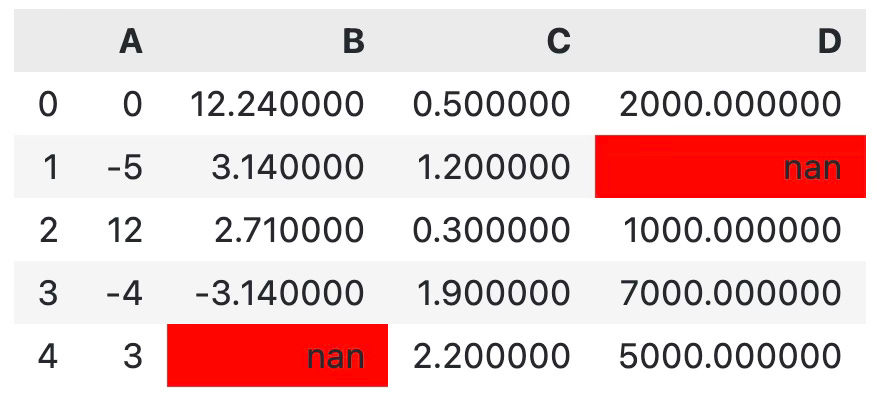
If you’re not satisfied with the default nan printed, you can also format missing values with a custom string:
df.style.format(na_rep="Missing").highlight_null()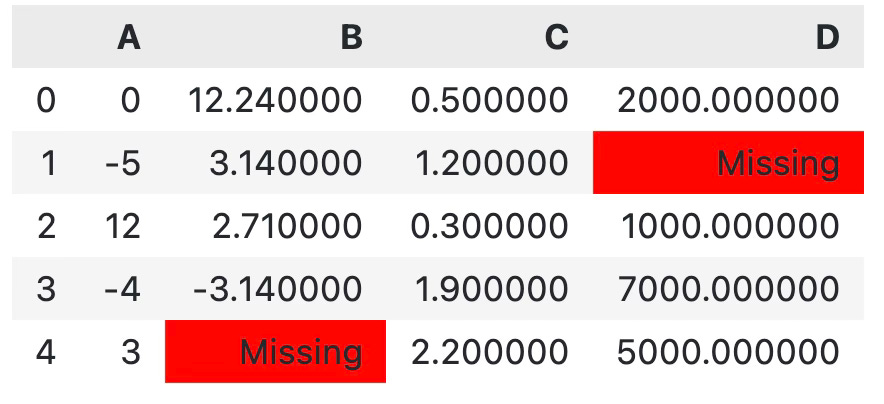
Neat! Let’s explore some other coloring options.
For example, the background_gradient() function will color the cells of individual rows with a gradient color palette. A bluish palette is used by default, and cells with higher values are filled with darker colors:
df.style.background_gradient()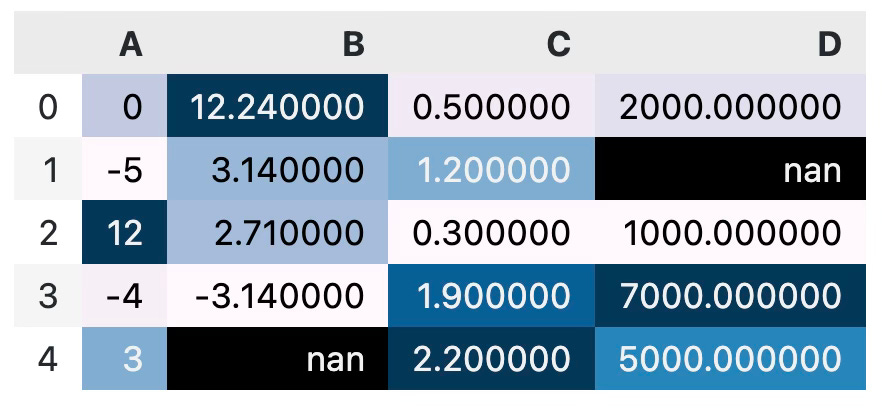
You don’t have to color the entire dataset — the subset parameter allows you to specify a list of columns you want to be colored:
df.style.background_gradient(subset=["B", "D"])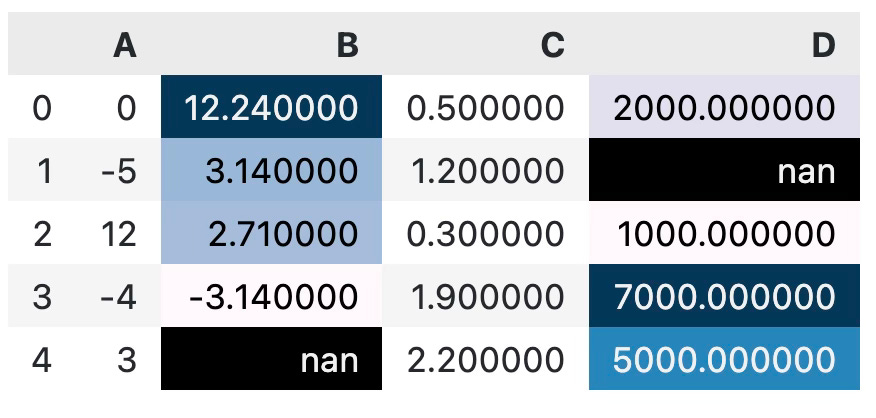
There’s also a way to change the color palette and explicitly set minimum and maximum values. These parameters are available in both background_gradient() and text_gradient() functions. Let's see how the latter one works first:
df.style.text_gradient(subset=["C"], cmap="RdYlGn", vmin=0, vmax=2.5)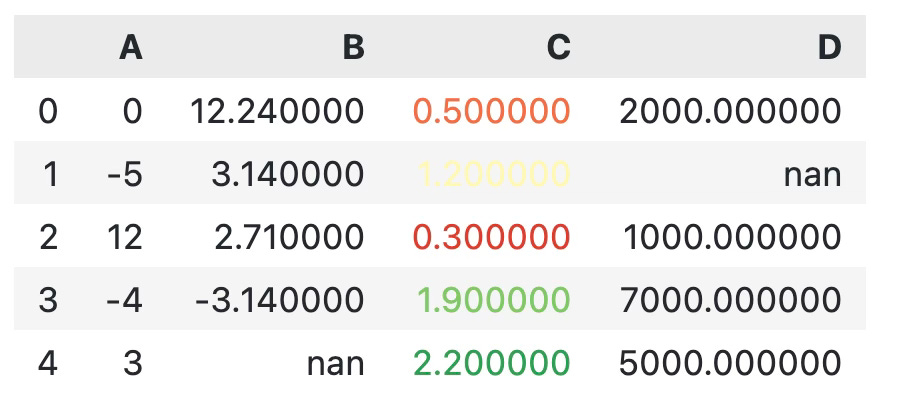
Nice, but not so easy on the eyes. The second value is somewhat hard to read. That’s why it’s better to color the entire cell, and not only the text:
df.style.background_gradient(subset=["C"], cmap="RdYlGn", vmin=0, vmax=2.5)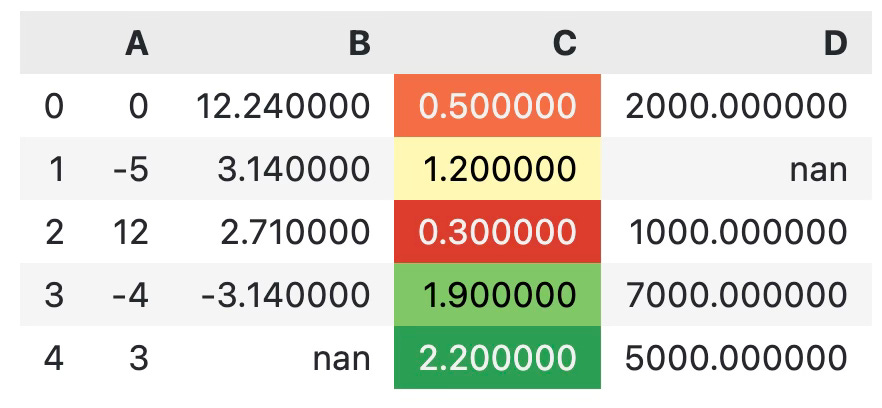
To add bar coloring to your DataFrames, simply call the bar() function:
df.style.format(precision=2).bar(color="orange")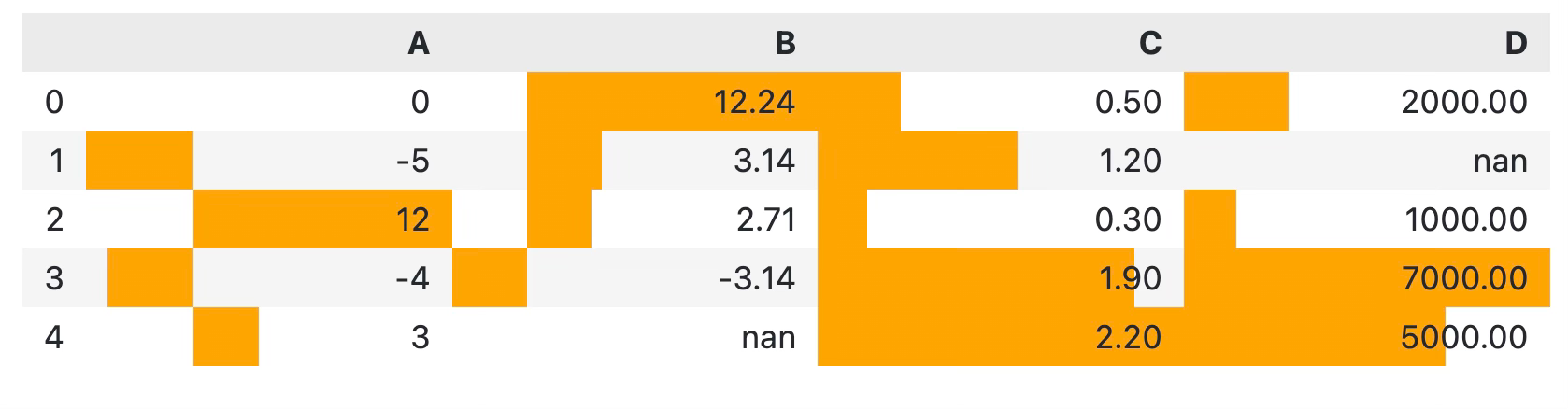
It’s not the best-looking table by default. There are some columns with negative values, so the bar goes both ways with no visual distinction. It’s a bad design practice, to say at least.
Also, it would help if there were borders between cells. Otherwise, the fill color just melts with the surrounding ones:
df.style.format(precision=2).bar(align="mid", color=["red", "lightgreen"]).set_properties(**{"border": "1px solid black"})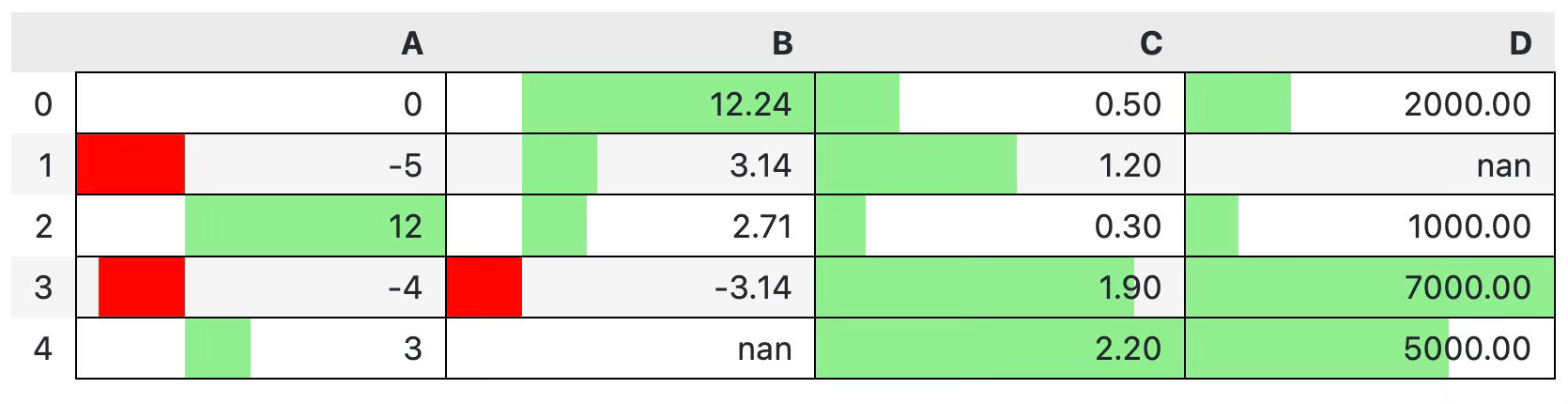
Much better!
If there was one point of concern many Pandas users have, that’s the text size. It’s too small if you’re working on a large monitor and don’t want to make everything bigger.
You can use the set_properties() function to pass in a dictionary of key-value pairs. Both keys and values come from CSS, and you'll feel right at home if you have any experience with web design.
The code snippet below sets a thicker gray border, applies a green color to the text, and increases the overall text size:
properties = {"border": "2px solid gray", "color": "green", "font-size": "16px"}
df.style.set_properties(**properties)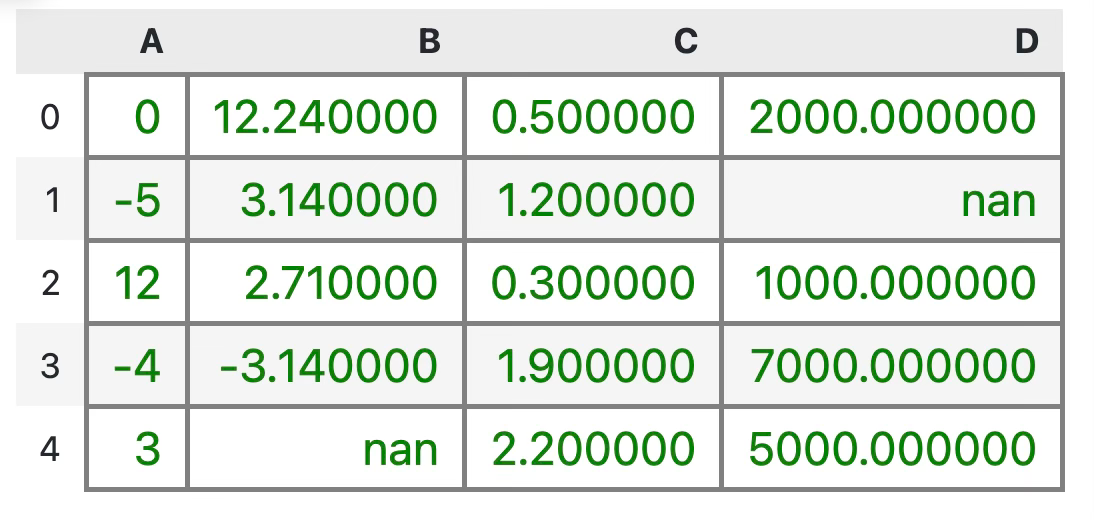
That’s about enough for the basic stylings. Next, we’ll really make the table stand out with a couple of advanced examples.
Advanced: Style Header Row and Index Column
Table design, or design in general, is highly subjective. But there’s one thing all good-looking tables have in common — an easy-to-distinguish header row. In this section you’ll learn how to style:
Table header row
Table index column
Table cells in a hover state
Let’s begin! We’ll declare three dictionaries — the first one is for the hover state, the second is for the index column, and the last one is for the header row. You can apply all of them to a DataFrame with the set_table_styles()function:
cell_hover = {
"selector": "td:hover",
"props": [("background-color", "#FFFFE0")]
}
index_names = {
"selector": ".index_name",
"props": "font-style: italic; color: darkgrey; font-weight:normal;"
}
headers = {
"selector": "th:not(.index_name)",
"props": "background-color: #800000; color: white;"
}
df.style.set_table_styles([cell_hover, index_names, headers])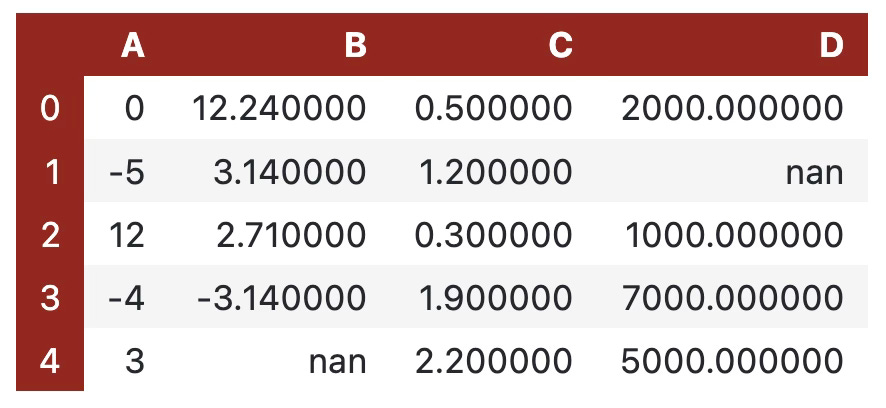
That’s a night and day difference from what we had before, but we can make it even better. For example, we can make all columns have the same width, center the cell content, and add a 1-pixel black border between them:
cell_hover = {
"selector": "td:hover",
"props": [("background-color", "#FFFFE0")]
}
index_names = {
"selector": ".index_name",
"props": "font-style: italic; color: darkgrey; font-weight:normal;"
}
headers = {
"selector": "th:not(.index_name)",
"props": "background-color: #93291E; color: white; text-align: center; font-size: 14px; font-weight: bold; border: 1px solid black;"
}
properties = {"border": "1px solid black", "width": "100px", "height": "35px", "text-align": "center"}
df.style.format(precision=2).set_table_styles([cell_hover, index_names, headers]).set_properties(**properties)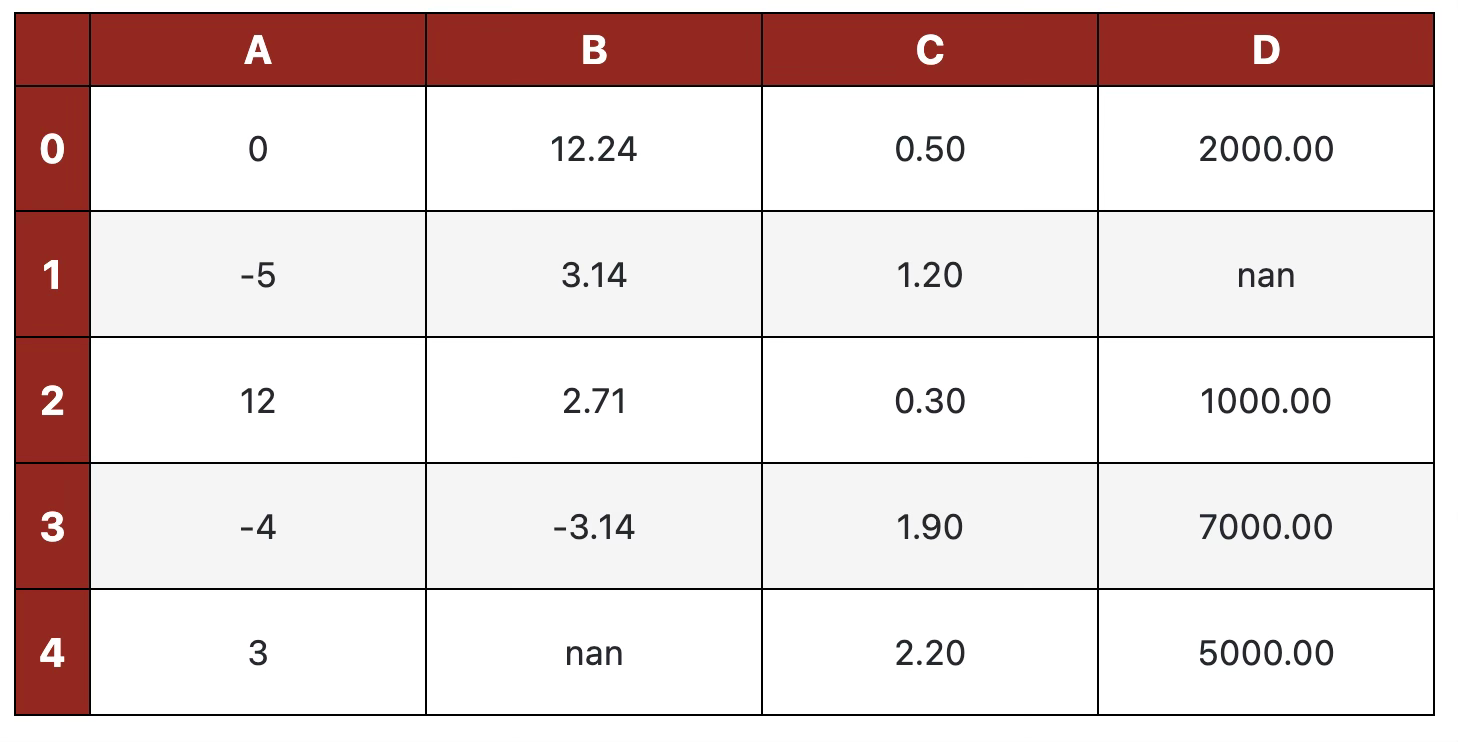
Now that’s one great-looking table!
Next, let’s see how to declare styles conditionally based on the output of Python functions.
Advanced: Declare Custom Styles with Pandas Styler
Sometimes the built-in styles just won’t cut it. Luckily, you can apply your own as a result of Python functions.
Here’s an example: The mean_highlighter() function will:
Color the cell red if the value is less than or equal to the mean
Color the cell green if the value is greater than the mean
Make the text white and bold in cases
Once outside the Python function, simply call apply() function from the Pandas Styles API:
def mean_highlighter(x):
style_lt = "background-color: #EE2E31; color: white; font-weight: bold;"
style_gt = "background-color: #31D843; color: white; font-weight: bold;"
gt_mean = x > x.mean()
return [style_gt if i else style_lt for i in gt_mean]
df.style.apply(mean_highlighter)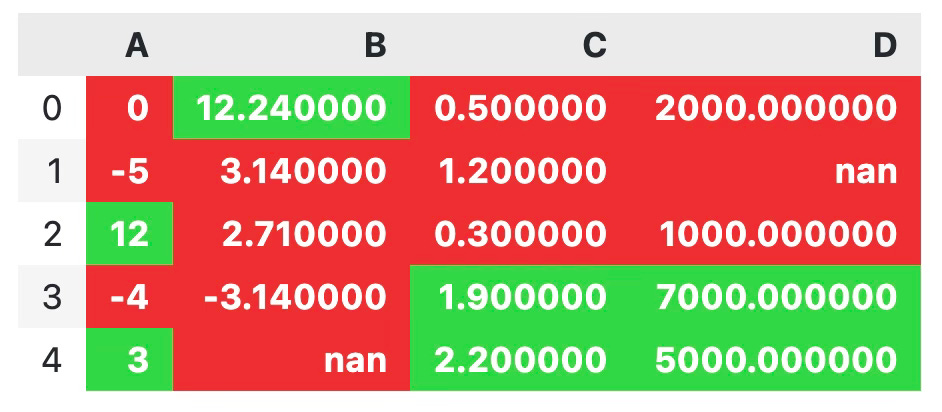
Not the prettiest colors, but definitely an easy way to set up conditional formatting in Python.
One common use case would be to make the text color of a cell red if the value is negative. Here’s how you would implement that:
def negative_highlighter(x):
is_negative = x < 0
return ["color: #EE2E31" if i else "color: #000000" for i in is_negative]
df.style.apply(negative_highlighter)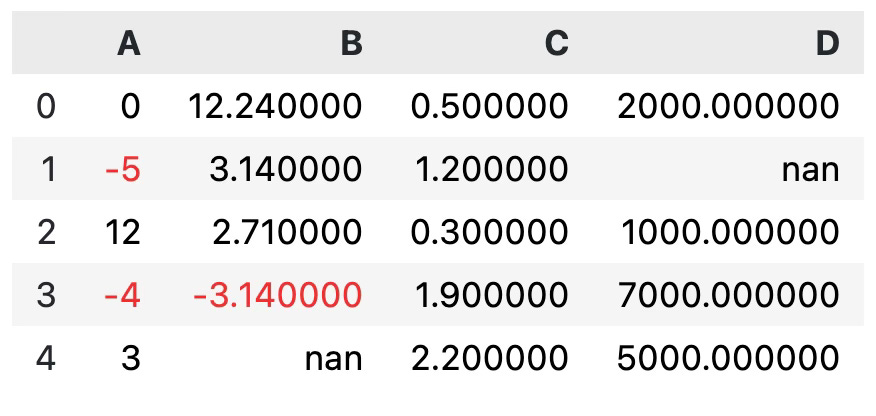
And with that knowledge under our belt, there’s only one thing left to discuss — exporting your styled tables.
How to Export Styled Pandas DataFrame to Excel
The result of all Pandas Style API functions is a Pandas DataFrame. As such, you can call the to_excel() function to save the DataFrame locally. If you were to chain this function to a bunch of style tweaks, the resulting Excel file will contain the styles as well.
Here’s the code for exporting a gradient-based colored table:
df.style.background_gradient(cmap="RdYlGn").to_excel("table.xlsx")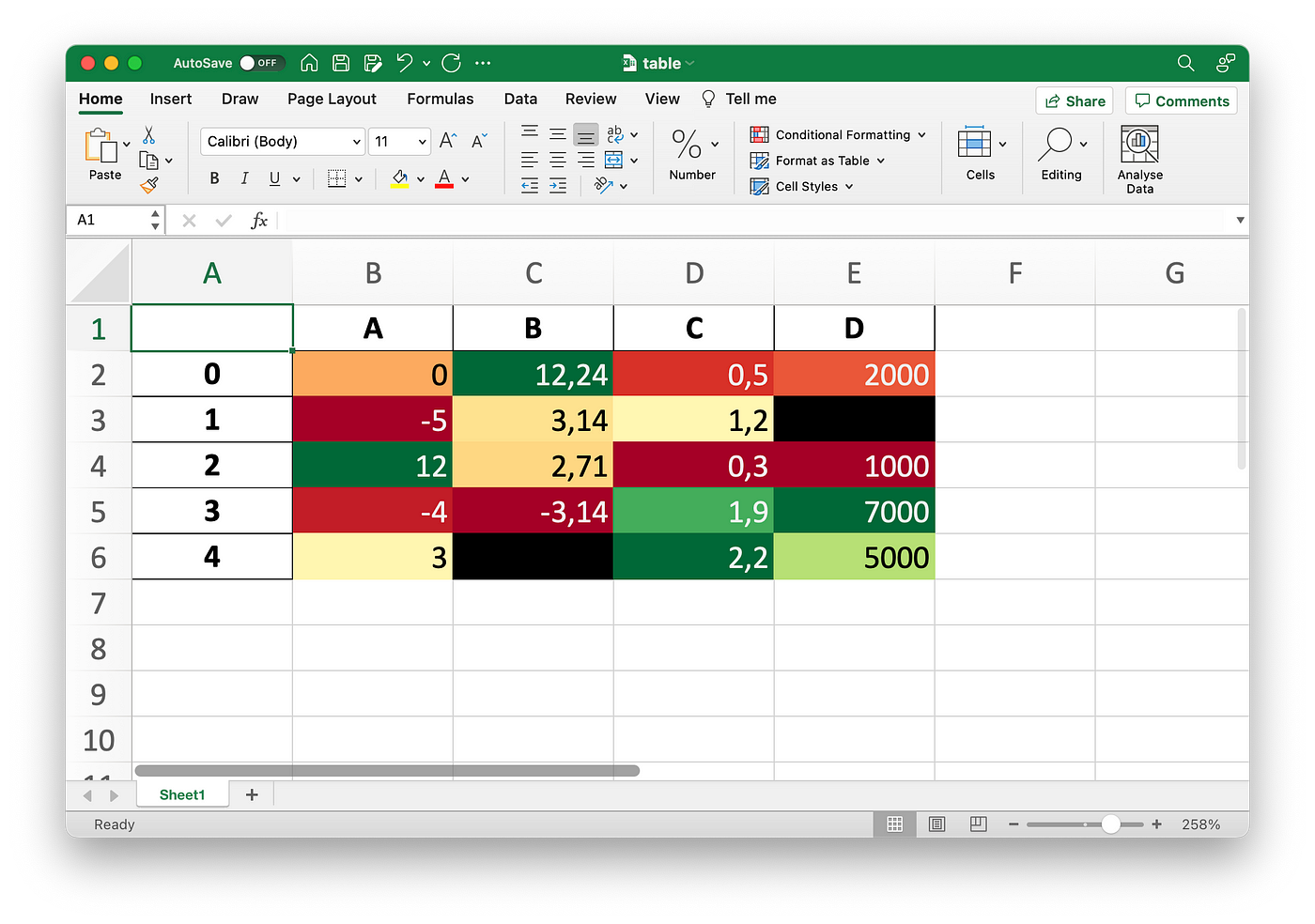
It’s something you can do in Excel too, but is much simpler to implement in Pandas.
Wrapping up
Today you’ve learned the ins and outs of the Pandas Style API. As I mentioned earlier, it’s an API I wish I learned sooner because it would save me so much time when working on presentations and papers.
There’s nothing you can’t do styling-wise with the tools and techniques you’ve learned today. Functions can be chained together when you want to apply multiple styles — for example, changing the number of decimal places and coloring the cells. Ordering matters, so keep that in mind.
Until next time.
-Dario